アドテクを中心として広告業界のトレンドについて発信をする『DAC AD TECH BLOG』。今回はDACが誇るデータサイエンティスト集団、ビッグデータ解析部についてご紹介します。DACでデータサイエンティストが誕生した背景や、現在彼らが実現しているデータドリブンな打ち手や施策について、ビッグデータ解析部の薩摩さん、吉村さんにお話を伺いました。

ビッグデータに価値を見出し、データドリブンなマーケティングを実現する
はじめに、ビッグデータ解析部とはどういう部署なのか教えてください。
薩摩:弊部は「ビッグデータを基盤に、広告主や媒体社とユーザのコミュニケーションを豊かにする」ことをミッションに、2013年に設立された部署です。弊社がもっているソリューションのデータすべてを解析し、お客様の課題解決やデータドリブンなマーケティングのための支援を行っています。
なぜDACで、データサイエンティスト集団が誕生したのでしょうか。
薩摩:DMP(データマネジメントプラットフォーム)※1という「データをいれるハコ」が世に出始めたことがきっかけです。
弊社では現在4億のcookieデータ(3rd partyデータ)を蓄積しているパブリックDMP「AudienceOne®」(以下AOne)を自社開発しています。AOneは、1st partyデータを収集・分析できる機能も持ちあわせており、この二つのデータを掛け合わせることによって、顕在化していない見込み顧客を含め、様々な層に対して最適なアプローチを実現しています。
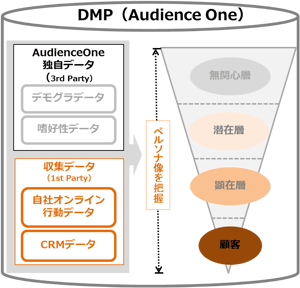
※DMP:「プライベートDMP」と「パブリックDMP」の大きく2種類のタイプが存在している。前者は基本的に、1st partyデータの収集、管理機能等をもつ。後者の「パブリックDMP」は、主に3rd party dataを保有している。パブリックDMPの詳細説明についてはこちら(リンク)。
薩摩:AOne開発当初は、蓄積するデータをビジネス価値に変える=料理(活用)ができる“料理の仕方”のプロが少ない状況でした。DMP単体ではただの「データをいれるハコ」でしかなく、そのデータを分析・活用することによって、はじめて真価を発揮します。その役割を担う存在としてデータサイエンティストが誕生しました。上述した「広告主・媒体社とユーザのコミュニケーションを豊かにする」というミッションを達成するため、日々データと向き合っています。

データサイエンティスト集団には、どのような能力を持った人たちが集結しているのでしょうか
薩摩:データを扱うチームに必要な視点は、大きく以下3つにわかれると考えています。
①データを扱う環境の整備(インフラのレイヤー)
②データをいかにうまく料理するか(データ分析のレイヤー)、
③データをいかにビジネスに昇華させるか(ビジネスのレイヤー)
この3つのレイヤーのいずれかまたは複数に特化・卓越したメンバーが集まり、互いに補完しあっているのが、DACのデータサイエンティスト集団です。
ビッグデータを活用できる具体的な施策とは
先程“料理の仕方”のプロとおっしゃいましたが、具体的に、ビッグデータ分析によって、どのようなマーケティング課題を解決しているのでしょうか。
吉村:そうですね。一例をあげるとすると、AOneの機能の一つとして、CV見込みの高いユーザに対して広告配信を可能にする「オーディエンス拡張」というものがあります。 リターゲティング配信は、一度自社サイトにアクセスしたユーザに広告を配信するのでCPAを低く抑えられますが、一方で一度アクセスしたユーザのみが対象となりますので配信対象となるユーザの数が少なくなり、結果CV数が少なくなってしまうことが課題として挙げられます。これを解決するのが「オーディエンス拡張」で、一言で言うとCVユーザと類似する行動傾向のある人に広告を配信するものです。DMPの3rd partyデータを活用することで、自社サイトに来訪していないユーザでもCV見込みの高いユーザを予測し、広告配信することができます。また、自社サイトデータだけでなく、購買データや顧客データ等、保有するオーディエンスデータと3rd partyデータを掛け合わせることで、さらに精度の高い広告配信が可能になります。
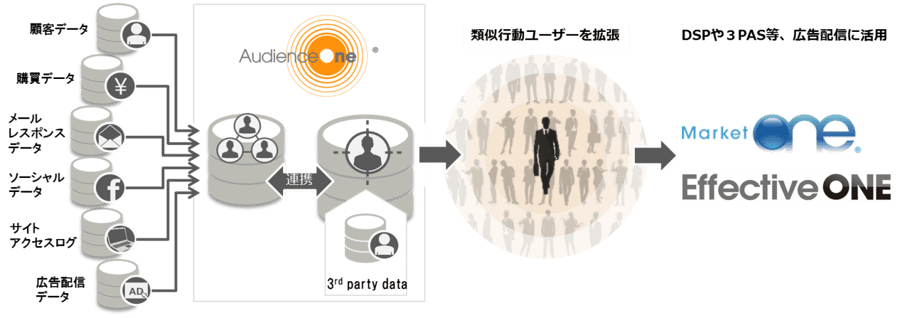
この「オーディエンス拡張」機能は、以前からAOneに搭載している機能ではありますが、引き続きこの精度を上げるための研究を日々行っております。最近の成果で言えば、 とある研究者の方のクラスタリング技術を活用して精度を上げたりと、外部の方との共同研究もさせていただいています。
またオーディエンス拡張だけでなく、クロスデバイスの研究や位置情報の活用など、様々な「データ」に付加価値を見出し活用するための方法を研究しています。
具体的には、どのような手法・思考でデータを分析しているのでしょうか。
吉村:R言語等の統計に特化したプログラミング言語を使って機械学習を活用する場合もありますし、エクセルでクロス集計して終わり、ということもあります。目的によって最適なアプローチは変わってきますし、扱うデータによっても適した分析手法は変わってきます。
「機械学習」に話を絞っても、データを「分類するのか」「予測するのか」でも使える手法は変わってきます。
「機械学習」は、「ビッグデータ」と共に注目されているワードの一つかと思います。そもそも「機械学習」とはどういったもので、なぜ注目されているのでしょうか。
吉村:どんな手法を用いたとしても、機械学習において一般的に言えることは、「無数にある性質をすべて定量的に評価し、その中から特徴的な性質だけを抽出できる」
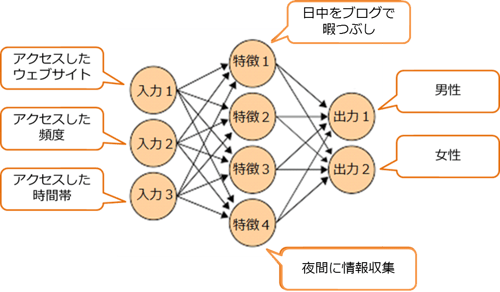
例えばウェブやアプリのアクセスログから性別を推定しようと思った時に、そのアクセスログにどんな性差が考えられるでしょうか。化粧品の情報サイトにアクセスしていたら女性っぽいですし、プロ野球の情報サイトを見ていたら男性っぽいと考えることができます。
もし、一般的にiPhone所持率が男性の方に偏っているとしたら、iPhoneを持っているユーザーは男性である確率が高くなりますし、男性の方が女性よりもインターネットにアクセスする頻度が多いかもしれません。

インターネット上にはウェブサイトが無限と言っても差し支えないほどに数多くあり、また、日々増加し続けています。例にあげたように、使用デバイスや特定のサイトへのアクセス頻度、アクセスする時間帯など、インターネットの“使い方”ひとつとっても、無数の切り口があります。これらをすべて人の目で追っていくことは不可能ですし、人の目で見るだけでは結局「気がする」程度の結論にしか終わりません。
ですから今、インターネット上のあらゆる行動を定量化し、抽出することのできる機械学習が評価されているのです。
まだ機械学習のイメージが固まりません。性質を定量的に評価し、抽出する、とありましたが、具体的な分析手法を教えてください。
吉村:機械学習の中でも最近話題の「ディープラーニング」を例にとってご説明しますね。機械学習がいかに有効な手段であるかも分かると思います。
まず最初に、かなり簡略化したものにはなりますが「ディープラーニング」を表す概念図を書いてみました。
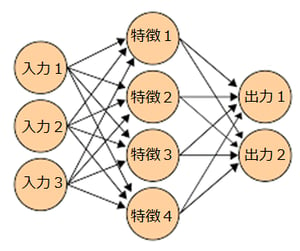
吉村:「入力層」と「特徴層」と「出力層」の大きく3つの層に分かれていて、入力⇒特徴⇒出力の順に矢印を指しています。
「ディープラーニング」は、あらかじめ3つの層にあてはめる数を指定しておくことによって、例えば「入力層を3つ」「特徴層を4つ」「出力層を2つ」などと数を指定しておくことで、各層間の関係を数値化してくれます。例えば、「入力1」と「特徴2」の関係の強さは0.3だ、「特徴3」と「出力2」の関係の強さは0.8だ、といったようにです。
上述しました性別の推定をこの概念図に当てはめてみると、入力1/2/3をそれぞれアクセスしたウェブサイト/アクセス頻度/アクセス時間帯、出力1/2を男性/女性とおくことで、ディープラーニングが適用できます。ディープラーニングが「特徴」にあたるものを自動的にあぶり出し、さらに関係の強さをたどることで、何が男性/女性に特徴的な性質なのかが数値でわかるようになるのです。
厳密に言うと、ディープラーニングはこの「特徴層」を何層も用意することで入力層と出力層の関係をより精確に記述できるようにしたものを指します。 繰り返しになりますが、機械学習はたくさんある性質をすべて定量的に評価してその中から特徴的なものを抽出してくれますので、手間と評価の2つの面で「人」の限界を解決してくれます。人の目では追えないほどのビッグデータを扱う時代になったからこそ、機械学習やデータ分析が活きてくるのです。
アナリティクス3.0の時代へ
今後の方向性を教えてください。
薩摩:DACの全部署とお客様がデータドリブンにビジネスを推進できる、意思決定にデータを活用できるような環境を整備していくことが我々の次のステップだと考えています。
米バブソン大学のトーマス・ダベンポート教授という方が、ビッグデータ活用の黎明期といえる今、「アナリティクス3.0」の時代が始まった、と言っています。
「アナリティクス1.0」の時代には、比較的小さいデータで、過去のできごとだけを記述すること(運用に生かされにくいレポート等)が主たる分析でした。、「アナリティクス2.0」の時代には、外部のデータも活用してサービスに落とし込むのが分析のメインでした。そして「アナリティクス3.0」の時代には、データを扱ってこなかった部署も、商品開発や意思決定等、データをビジネスに活かしていく時代だと定義しています。
ちょうど1年前、「時代は2.0の真っ只中」と言われていたように思いますので、今はアナリティクス2.0から3.0に移行しつつあるフェーズではないでしょうか。
この流れは冒頭で述べた、我々データサイエンティストのミッションである「ビッグデータを基盤に、広告主や媒体社とユーザのコミュニケーションを豊かにする」ことと一致しています。
アナリティクス2.0で言われているデータを活用した商品・サービスは引き続き開発していく一方で、アナリティクス3.0の時代を切り拓いていく姿勢をもって、日々挑戦を続けていきたいと考えています。
薩摩さん、吉村さん、ありがとうございました。
Markezineにて、ビッグデータ解析部のメンバーが執筆している記事もございますので、こちらも併せてご覧ください。
今回ご紹介した内容にご興味を持っていただいた方は、以下よりお問い合わせください。







